ONNX2WebNN - 将 Web AI 框架开销降低至 1/400
浏览器中的机器学习从早期依赖 JavaScript 在 CPU 上运行的时代至今,已经取得了长足的进步。Web 神经网络(WebNN)API 代表了最新的演进 - 一个直接利用硬件加速的 Web 标准,无论是 CPU、GPU 还是 NPU。
WebNN 特别有趣的是其隐私优先的方法。所有推理都在用户设备上本地进行。没有数据被发送到服务器,没有对远程服务的 API 调用 - 一切都保持在本地。在隐私问题成为焦点的时代,这种本地优先的方法是一个重大优势。
WebNN API 更像是其他工具可以在其上构建的基础。您可以通过熟悉的 JavaScript ML 框架使用它,或者直接使用原生 JavaScript。
两种路径,两种不同的权衡
WebNN 为您提供了两种构建 AI 驱动 Web 应用的主要方式,它们在方法上截然不同。
框架路径:熟悉的领域但有开销
第一种选择是通过已建立的 JavaScript ML 框架(如 ONNX Runtime Web、Transformers.js 或 LiteRT)使用 WebNN。如果您以前使用过这些框架,这是一条舒适的路径 - 您得到了您知道的相同 API,但 WebNN 在底层提供硬件加速。您可以参考 Transformers.js 和 ONNXRuntime 获取更多信息。
框架为您处理所有 WebNN 复杂性,并在不支持硬件加速时优雅地回退。
框架权衡:
- 包大小影响:框架通常会为您的应用增加 2-20 MB
- 运行时开销:模型需要预处理,可能会延迟首次推理
- 控制较少:框架抽象可能隐藏优化机会
- 依赖复杂性:需要管理更多依赖项和潜在的安全考虑
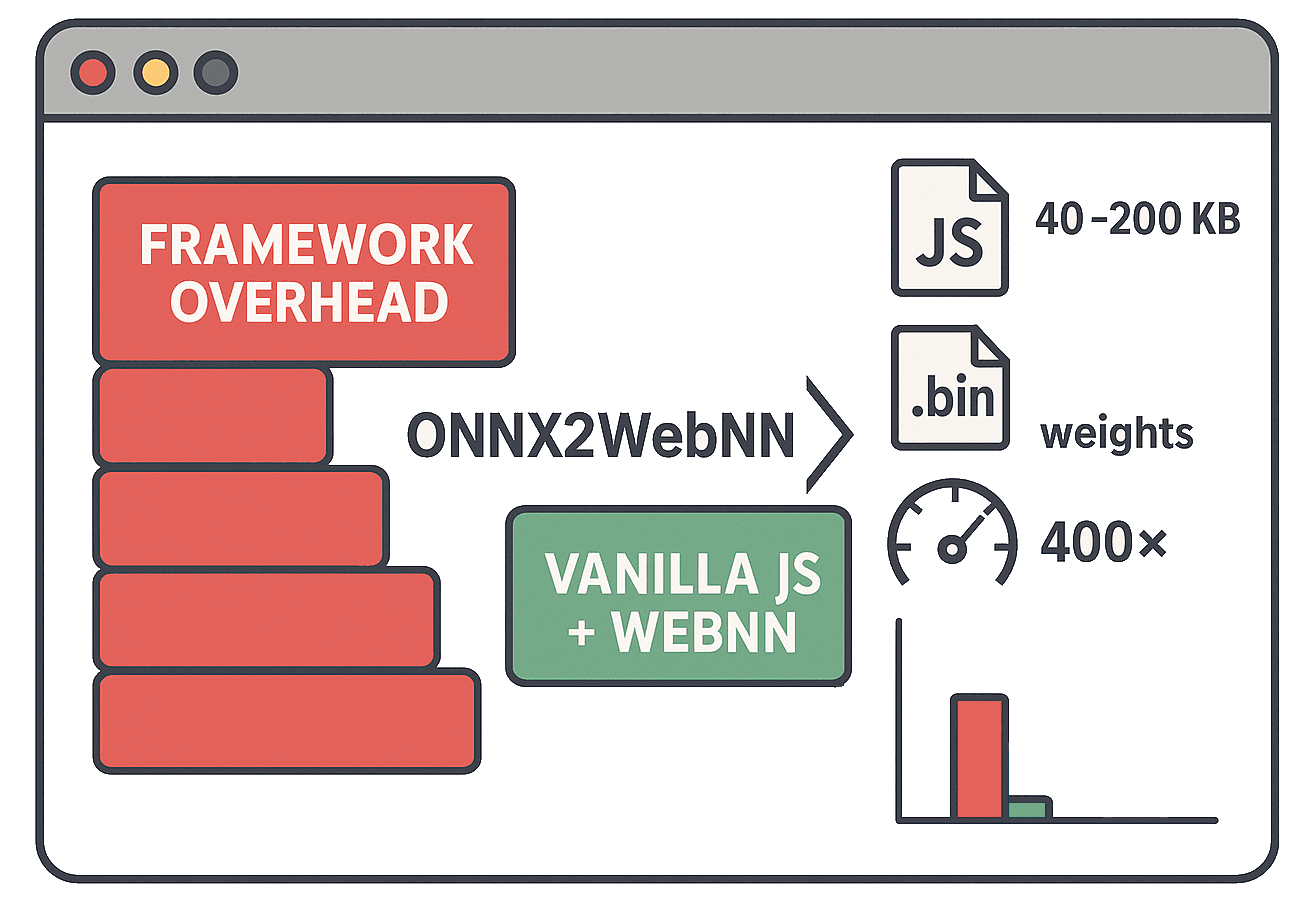
 图 1:包大小比较(JS ML 框架 vs WebNN 原生 JavaScript)
图 1:包大小比较(JS ML 框架 vs WebNN 原生 JavaScript)
由于包大小意外地过大,许多 Web 应用开发人员迫切需要解决这个问题的方案。下面的第二种选择有效地解决了这个挑战。
原生 JavaScript 路径:最大控制,最小开销
第二种选择是直接通过原生 JavaScript 使用 WebNN。这意味着使用原始 WebNN API 手动构建神经网络图。这需要更多工作,但它给您完全控制模型执行的每个方面。
原生 JavaScript 的优势:
- 极小的包大小:没有框架开销 - 只有您的模型代码和权重
- 最大性能:无框架开销的直接访问
- 完全控制:微调模型加载和执行的每个细节
- 透明度:您确切知道每一步发生了什么
- 自定义优化:为您的特定用例实现专门的优化
原生 JavaScript 的挑战:
- 开发复杂性:需要比框架解决方案多得多的代码
- 模型转换:需要从标准格式转换为 WebNN 兼容代码
- 回退责任:当 WebNN 不可用时,您需要处理优雅降级
- 维护开销:更新和优化需要手动实现
当包大小变得至关重要时
这是原生 JavaScript 方法真正发光的地方。如果您正在构建对包大小敏感的应用 - 任何加载时间直接影响用户体验的场景 - 大小差异是显著的。 让我们分析一下数字:
基于框架的实现:
- 框架库:2-20 MB
- 模型权重:400KB-50 MB(取决于您的模型)
- 生成的包开销:总共 2.4-70 MB
WebNN 原生 JavaScript 实现:
- 生成的 JavaScript 代码:40-200 KB
- 模型权重:400KB-50 MB(相同权重)
- 总开销:0.44-50.2 MB
这 2-20 MB 的差异转化为现实世界的影响。在慢速 3G 连接上,节省 3 MB 意味着用户可以提前 15-20 秒看到您的应用。对于许多应用,这是用户留下或离开之间的区别。 除了大小节省,WebNN 原生 JavaScript 还消除了运行时预处理开销。
代码生成的改变者
这里是 WebNN 原生 JavaScript 变得有趣的地方:您不必自己编写所有低级代码。WebNN 社区正在构建复杂的代码生成工具,自动将标准 ML 模型转换为优化的原生 JavaScript。
这些工具在”易于开发”和”高效运行”之间架起了桥梁。您可以获得 WebNN 原生 JavaScript 的包大小和性能优势,而无需手动编码复杂性。
ONNX2WebNN:命令行强力工具
ONNX2WebNN 是一个基于 Python 的命令行工具,非常适合自动化工作流程和开发管道。它接收 ONNX 模型并生成清洁的 WebNN JavaScript 代码。
生成 WebNN JavaScript 模型
大多数 ONNX 模型包含动态维度 (dynamic dimensions) - 可以在推理运行之间变化的灵活输入形状 (shapes)。WebNN 在固定维度下表现最佳。
第一步是使用 onnxruntime_perf_test 工具将您的动态 ONNX 模型转换为静态版本。
onnxruntime_perf_test -I -r 1 -u mobilenetv2-12-static.onnx -f batch_size:1 -o 1 mobilenetv2-12.onnx创建一个包含生成文件的”mobilenet”文件夹:
mkdir mobilenet然后运行以下命令为静态 ONNX 模型创建 WebNN JavaScript 模型:
python onnx2webnn.py -if ../sample_models/mobilenetv2-12-static.onnx -oj mobilenet/mobilenet.js理解生成的代码
这会生成两个文件:一个包含您的 WebNN 模型实现的 .js 文件和一个包含模型权重的 .bin 文件。还会生成一个 index.html 用于测试 WebNN 模型。所有处理都在您的机器上本地进行 - 您的模型数据永远不会离开您的环境。
在包含生成模型文件的文件夹中启动 node.js http-server 并使用 URL http://localhost:8080/ 启动 Web 浏览器。
http-server生成的 JavaScript 文件通常包含两个主要函数:
build()- 构建 WebNN 计算图run(inputs)- 使用提供的输入执行推理
NCHW 和 NHWC 布局支持
ONNX2WebNN 特别聪明的是它对数据布局的处理。不同的 WebNN 后端更喜欢不同的张量布局(NCHW vs NHWC),性能可能会根据这种选择而显著变化。
# 生成两种布局版本
python onnx2webnn.py -if model.onnx -oj model_nchw.js
python onnx2webnn.py -if model.onnx -oj model_nhwc.js -nhwc您的应用然后可以动态选择最佳版本:
const deviceType = 'gpu'; // 或 'cpu', 'npu'
const context = await navigator.ml.createContext({deviceType});
const layout = context.opSupportLimits().preferredInputLayout;
let webnnModel;
if (layout == 'nhwc') {
webnnModel = new MobilenetNhwc();
} else {
webnnModel = new Mobilenet();
}
// 以首选布局加载权重并构建图
await webnnModel.build({deviceType});
// 使用 webnnModel.run() 进行推理我们观察到仅通过使用后端首选布局就能获得显著的性能改善,MobileNetV2 实现了 3 倍的性能提升。这是区分演示代码和生产就绪实现的优化之一。
生成 QDQ WebNN 模型
ONNX2WebNN 的突出特性之一是其对使用 QDQ(量化 - 反量化)格式的量化模型的支持。量化模型可以显著减少内存使用并提高推理速度,使其非常适合资源受限的 Web 部署。 但是,使用 QDQ 模型需要一个关键的预处理步骤。WebNN 规范对 quantizeLinear 和 dequantizeLinear 操作要求基于张量秩和量化轴进行适当的张量重塑。为了确保这正常工作,您的 ONNX 模型必须包含所有输出张量的完整形状信息。
pip3 install onnxsim
onnxsim ../sample_models/mobilenetv2-12-qdq-static.onnx ../sample_models/mobilenetv2-12-qdq-static-simplified.onnx之后,使用以下命令行生成 WebNN 模型
python onnx2webnn.py -if ../sample_models/mobilenetv2-12-qdq-static-simplified.onnx -oj mobilenet_qdq/mobilenet_qdq.js对于 NHWC 模型,使用
python onnx2webnn.py -if ../sample_models/mobilenetv2-12-qdq-static-simplified.onnx -oj mobilenet_qdq_nhwc/mobilenet_qdq_nhwc.js -nhwcModel2WebNN: 易于使用的交互式工具
Model2WebNN 采用了完全不同的方法 - 它完全在您的浏览器中运行。所有模型转换和代码生成都在客户端进行,这意味着您的模型永远不会离开您的机器。
当您使用专有或敏感模型时,这种基于浏览器的方法是无价的,即使上传到”安全”转换服务也不可接受。
工作流程允许您:
- 打开 Model2WebNN 并上传您的模型。
- 它解析
.onnx和.tflite模型文件以生成自包含的 JavaScript。 - 生成的代码使用 WebNN MLGraphBuilder API。
您首先将模型(ONNX、TensorFlow Lite 或其他格式)加载到工具中。它生成准备直接调用的带纯 MLGraphBuilder 代码。
这个工具特别好的地方是它如何处理动态维度。许多模型都有符号维度 (symbolic dimensions)(如可变 batch_size),生成器提供了一个清洁的界面来用 WebNN 可以高效处理的具体值覆盖这些值。
WebNNUtils:替代工具
WebNNUtils/OnnxConverter 代表了 Microsoft 的 ONNX 到 WebNN 转换的实验性方法。
WebNNUtils 背后的关键洞察是完全消除运行时开销。虽然 JavaScript ML 框架在模型加载期间执行昂贵的预处理 - 确定输入形状、在 CPU 和 GPU 之间分区操作、优化计算图 - WebNNUtils 在编译时完成所有这些工作。多步骤过程处理复杂的优化,如自动确定哪些操作应该在 CPU vs GPU 上运行,确保适当的依赖排序。
实际考虑:何时选择什么
JavaScript ML 框架和 WebNN 原生 JavaScript 之间的选择不仅仅是技术性的 - 它是关于将您的方法与项目的实际约束和需求相匹配。
选择框架集成:
- 开发速度比包大小更重要
- 您的团队已经熟悉 ML 框架
- 应最小化维护开销
- 您正在构建概念验证或 MVP
选择 WebNN 原生 JavaScript:
- 包大小直接影响用户体验
- 您正在构建专门的 AI 应用
- 隐私要求阻止框架依赖
- 您有用于自定义优化的开发资源
当前状态
WebNN 的浏览器支持正在快速演进。Google Chrome 和 Microsoft Edge 提供标志后的实验性支持 。轨迹很明确 - WebNN 将比预期更快地广泛可用。
工具生态系统也在成熟。所有三个代码生成工具都在积极维护,在模型兼容性和优化能力方面不断改进。对于包大小至关重要的应用,WebNN 原生 JavaScript 今天提供了引人注目的优势。对于快速开发和广泛兼容性,框架集成提供了更平滑的路径。
WebNN 作为标准的美妙之处在于它支持两种方法。您可以从框架集成开始以获得更快的开发速度,然后迁移到原生 JavaScript 以获得特定的性能关键组件。或者您可以从一开始就使用 WebNN 原生 JavaScript 以获得最大控制。
无论您是在构建一个轻量级移动体验(其中每个千字节都很重要),还是一个功能齐全的 AI 应用(其中开发速度最重要),WebNN 都提供了前进的道路。关键是诚实地评估您的约束并选择最好地服务于用户需求的方法。
WebNN 是一个不断发展的标准,在浏览器支持和工具方面有快速改进。在开始实现之前,请查看当前的兼容性文档以了解最新功能。
关于作者
- 张敏 :英特尔软件工程经理。专注于 Intel 客户端平台上的 Web 神经网络(WebNN)API 实现。他是 Intel Web 平台工程团队的一员。
- 胡宁馨 :英特尔首席工程师,W3C Web 神经网络规范的发起人和联合编辑,Chromium 贡献者和 Chromium WebNN 组件的共同拥有者。
- Web Guru @ medium.com